
The Caveman Prompt: How to Drastically Cut Your AI Token Costs
Learn how to drastically reduce your LLM API costs using Context Engineering and the Caveman Prompt. Discover practical strategies to optimize AI token usage today.
Have you ever checked your API usage dashboard for OpenAI or Anthropic and felt a sudden wave of panic? You are definitely not alone. As developers and businesses build more everyday tools powered by Large Language Models, the cost of running these systems is becoming a serious concern. While the models themselves are getting cheaper per request, our appetite for feeding them massive amounts of data is growing even faster.
Most people start by focusing entirely on writing better questions to get better answers. They spend hours tweaking the tone, adding examples, and refining their instructions. But there is a silent budget killer lurking behind the scenes. It is token usage. Whether you are building an automated customer support agent or just relying on ChatGPT for daily coding help, understanding how tokens work is the difference between a high performing system and an unexpectedly huge monthly bill.
Today, we are going to explore a surprisingly simple technique called "Caveman Prompting" and dive deep into the broader world of Context Engineering. By the time you finish reading, you will know exactly how to cut your AI token costs by sixty to seventy percent without losing any output quality. Let us get started!
What Exactly Is A Token?
Before we can optimize anything, we need to understand the fundamental currency of Large Language Models. These systems do not read text the way humans do. They do not see sentences or paragraphs. Instead, they break everything down into tiny computational units called tokens.
You can think of a token as a small chunk of a word. A general rule of thumb is that one token equals roughly four characters of standard English text. Short, common words like "cat" might be a single token. Longer or more complex words like "optimization" might be split into three or four separate tokens.
Why does this matter? Because you pay for every single token that goes into the model as part of your prompt, and you pay for every single token the model generates in its response.
Here is the catch that trips up many beginners. The input and output token prices are usually different. Generating new text requires much more computational power than reading provided text. Therefore, output tokens are typically significantly more expensive than input tokens.
This means that if you ask an AI model to write a sprawling, three thousand word essay when you only needed a short summary, you are wasting the most expensive resource in the system. The secret to building cost effective AI applications is tightly controlling both what you feed into the model and exactly how much it gives you back.
The Danger of "Everything" Chats
One of the most common mistakes I see developers and power users make is treating their AI chat interface like an infinite notebook. They start a new conversation on Monday to brainstorm marketing ideas. On Wednesday, they use the exact same chat window to debug a complex React component. By Friday, they are pasting in huge legal contracts and asking for summaries.
This approach creates a massive computational burden. Every time you send a new message in a continuous thread, the model does not just read your latest question. It has to re-read and process every single message, prompt, and response that came before it in that specific session.
Imagine carrying a backpack. Every time you ask a question, you add a rock to the bag. Over a few days, the bag gets incredibly heavy, and every new step takes an enormous amount of energy. This is exactly what happens to a Large Language Model. The system must process thousands of irrelevant tokens about marketing strategies just to answer your question about a React bug.
This phenomenon is known as context bloat. As the conversation history grows, your input token count skyrockets for every single prompt. This not only drives up your costs, but it also heavily degrades the quality of the response. The model has to sift through so much noise that it might hallucinate details or lose the thread of your actual question.
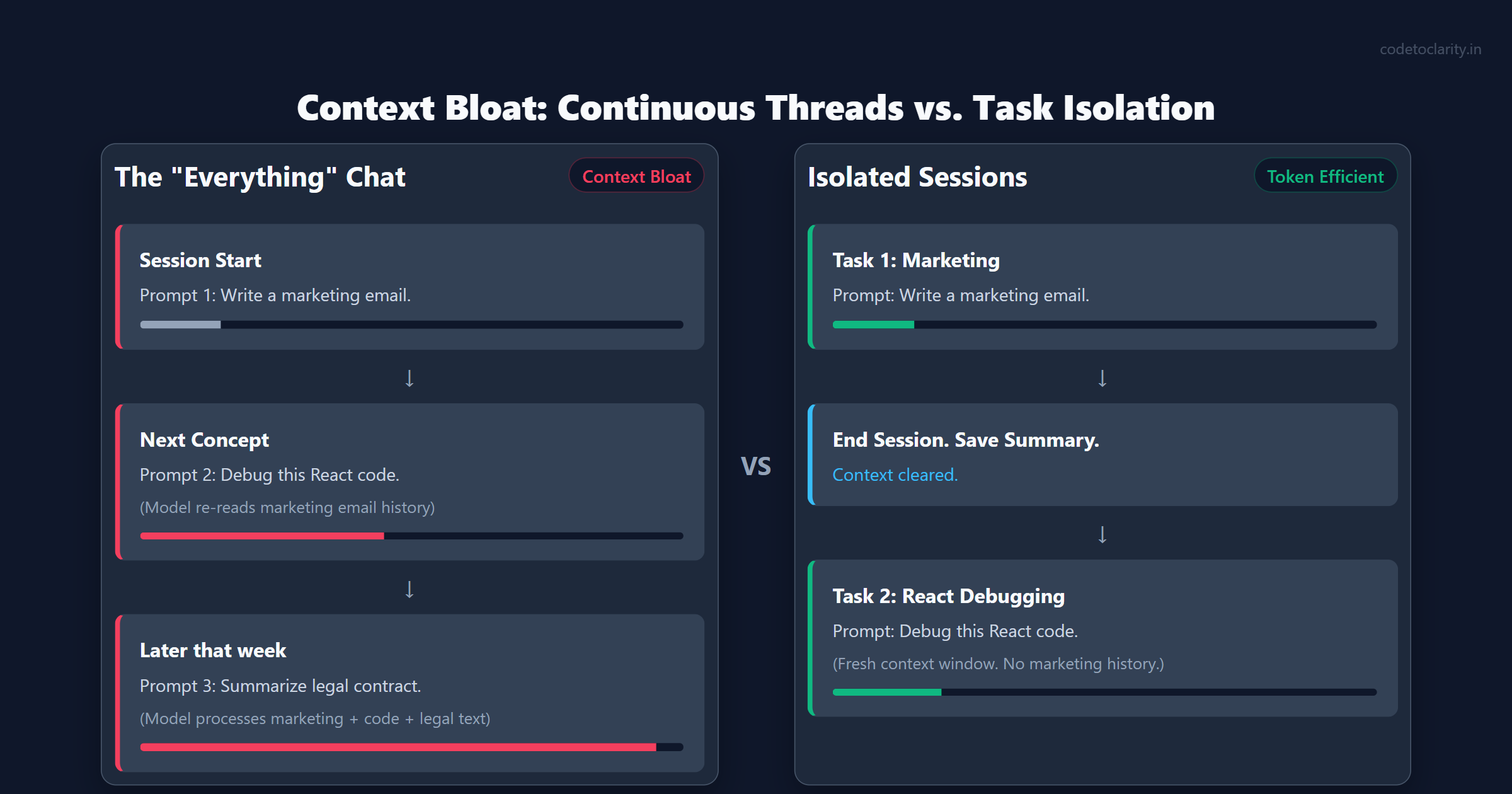
The simplest fix is to start fresh sessions frequently. Treat each chat like an isolated task. Once the task is completed, summarize the key findings, open a brand new session, and paste in the summary as your starting context. This single habit can dramatically reduce your token usage overnight.
The Caveman Prompt Strategy
Now we arrive at the most entertaining, yet highly effective, strategy for token reduction. It is known as the Caveman Prompt. At first glance, it sounds completely ridiculous. But once you understand the mechanics underlying Large Language Models, it makes perfect sense.
When an AI gives you an answer, it natively tries to sound polite, grammatical, and conversational. If you ask a simple database query question, the model might respond by saying, "I would be happy to help you with that! To combine data from two tables based on a common key, you can make use of a JOIN operation in SQL."
The core meaning in that sentence is simply "Use a SQL JOIN." But the model surrounds the signal with "glue words". Glue words are the conversational pleasantries, transitional phrases, and grammatical scaffolding that make sentences comfortable for humans to read. Unfortunately, these glue words add absolutely zero logical value to the technical answer, and you are paying for every single one of them.
The Caveman Prompt solves this by instructing the model to completely ignore grammar, politeness, and filler words. You explicitly tell the AI to produce broken, highly compressed, and aggressively terse language.
A sample instruction might look like this:
"You are an AI that speaks in caveman style. Rules: No filler words. No politeness. No long explanations. Keep only meaningful words. Prefer symbols like arrows and equal signs. Output maximum meaning with minimum tokens."
If you apply this instruction, that same long winded SQL answer transforms into:
"Use JOIN. Match key."
This is incredibly profound for developers building automated systems. An API returning JSON data to a background processing script does not need a polite introduction. It just needs the raw data.
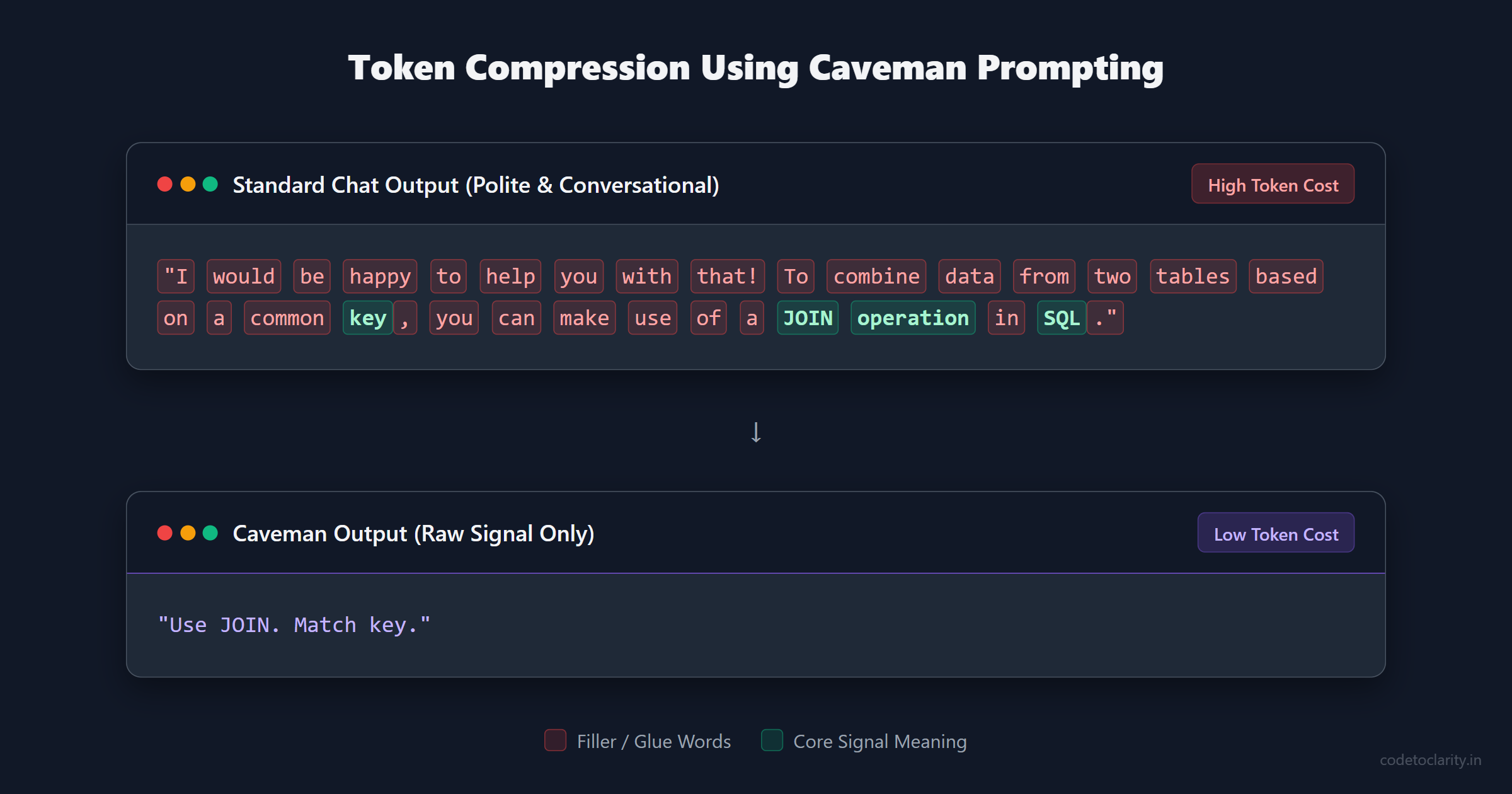
By applying Caveman Prompting in automated scripts or backend workflows, developers regularly see a reduction in output tokens by forty to seventy percent. The model is still performing the exact same high level reasoning internally. It is just expressing the final result in a highly compressed format, saving you money and drastically lowering the latency of the response.
Automating It: The Caveman Tool
You do not even have to continually write out caveman instructions manually. Open source developers have already built plugins to automate this behavior. A perfect example is the popular GitHub repository called caveman, which provides an installable plugin for over thirty popular AI development agents like Claude Code, Cursor, Windsurf, and Copilot.
Once installed, you can simply type /caveman to toggle the mode on or off. The tool automatically instructs the underlying language model to drop all conversational fluff and emit severely compressed responses. It includes different "intensity levels" (from Lite up to an Ultra minimal mode) and even comes with dedicated commands like /caveman-commit and /caveman-review to apply these token saving principles to your everyday Git workflows without extra effort. According to its benchmarks, using a tool like this effortlessly cuts output tokens by an average of sixty-five percent while retaining complete technical accuracy.
From Prompt Engineering to Context Engineering
The Caveman Prompt is just one specific tactic. If we zoom out, we are seeing the rise of an entirely new discipline called Context Engineering. While prompt engineering focuses on asking the right questions, context engineering focuses on managing the flow of information.
The core philosophy of context engineering is simple. You must ruthlessly filter the information you pass to a model, delivering the highest possible signal with the lowest possible noise.
Think of it as preparing ingredients for a chef. You do not just dump the entire grocery bag onto the kitchen counter. You wash the vegetables, chop them to the right size, and provide only exactly what the recipe calls for.
When you attach large documents to your prompts, you should rarely upload the whole file. If you are asking a question about the pricing section of a massive service contract, do not upload all fifty pages. Use a simple script or a smaller, cheaper tool to extract just the pricing pages, then send only those specific pages to your main premium model.
This leads us to the concept of model routing. Not every task requires the heavy lifting of a flagship model like GPT-4o or Claude 3.5 Sonnet. For simple tasks like formatting a block of text, extracting email addresses, or summarizing a paragraph, you should always route the request to a much smaller, cheaper model. Reserve the expensive, high context models strictly for tasks that demand deep logical reasoning or complex coding.
You can learn more about how powerful models handle varying context windows by reading the Anthropic Context Window Documentation. They provide excellent technical insight into how irrelevant data dilutes the attention mechanism of neural networks.
Monitoring and Measuring Token Usage
Before you can reduce your costs, you need to know exactly where those costs are coming from. Measuring token usage should be a core part of your daily development routine. Many platforms offer fantastic built in dashboards, but you can also measure tokens programmatically.
If you are using Node.js or Python, there are official libraries provided by the framework creators to count tokens locally before you even send the request over the network. For example, OpenAI provides a library called tiktoken. You can pass your entire prompt string into tiktoken to see exactly how many tokens it consumes. This is incredibly helpful when you are working on preprocessing large documents. If you notice a document translates into five thousand tokens, you immediately know that you need to compress or summarize it first.
Additionally, always log token usage in your application databases. If you build a feature that generates weekly reports using an AI model, log the input tokens and output tokens alongside the user ID. After a month, you can run a simple SQL query to find out which specific users or which specific prompts are driving up your costs. You will often find that a single poorly optimized prompt is responsible for the vast majority of your bill.
Four Specific Tactics for Everyday Token Optimization
If you want to start optimizing your AI workflows today, here is a practical checklist of four specific tactics you can implement immediately.
First, enforce structured outputs. Whenever possible, ask the model to return a structured format like JSON instead of paragraphs of text. You can even provide an exact template for the CodeToClarity backend service to follow. Structured data naturally forces the model to skip the polite introductory chatter and get straight to the facts. It is also infinitely easier to parse programmatically in your applications.
Second, avoid iterative rewrite loops. We have all done it. We ask the AI to write an email. We reply to make it shorter. Then we reply to make it more professional. Each iteration forces the model to read the entire combined history of previous failed attempts. Instead of taking five steps to reach your goal, take a moment to write one highly specific, detailed prompt from the start. Instruct the model on tone, length, and specific vocabulary in the very first message.
Third, specify precise length limits. Because output tokens are the most expensive part of a transaction, you must place strict guardrails on them. Do not just ask for a summary. Ask for a maximum three bullet point summary containing fewer than fifty words total. Models are surprisingly good at adhering to length constraints if you are explicit about them.
Fourth, utilize prompt caching if your AI provider supports it. Both OpenAI and Anthropic recently introduced mechanisms to cache large, static system prompts. If you have a massive block of specific coding guidelines or documentation that remains unchanged across many requests, formatting it correctly allows the provider to cache those tokens. This means you do not have to pay the full price for those static tokens on every single subsequent request. You can check out the OpenAI Prompt Caching Guide to see how caching large instructions saves money and drastically speeds up the time to first byte.
Building AI Agents with Lean Context
The principles of context engineering become absolutely critical when you start building AI agents. An AI agent is essentially a program that runs in a loop. It decides what to do, takes an action, observes the result, and repeats the process until a goal is achieved.
Imagine an agent tasked with researching competitors. In a poorly designed system, the agent might scrape a website, dump the entire raw HTML into its prompt, and ask itself what to do next. If it loops twenty times, passing that massive HTML block back and forth every single time, your API cost will explode exponentially.
A well designed agent employs strict context isolation. It uses a small, cheap model to parse the HTML and extract only the relevant text. Then, it uses a Caveman Prompt to compress that text into a dense list of facts. Finally, it passes only that small list of facts to the primary reasoning model.
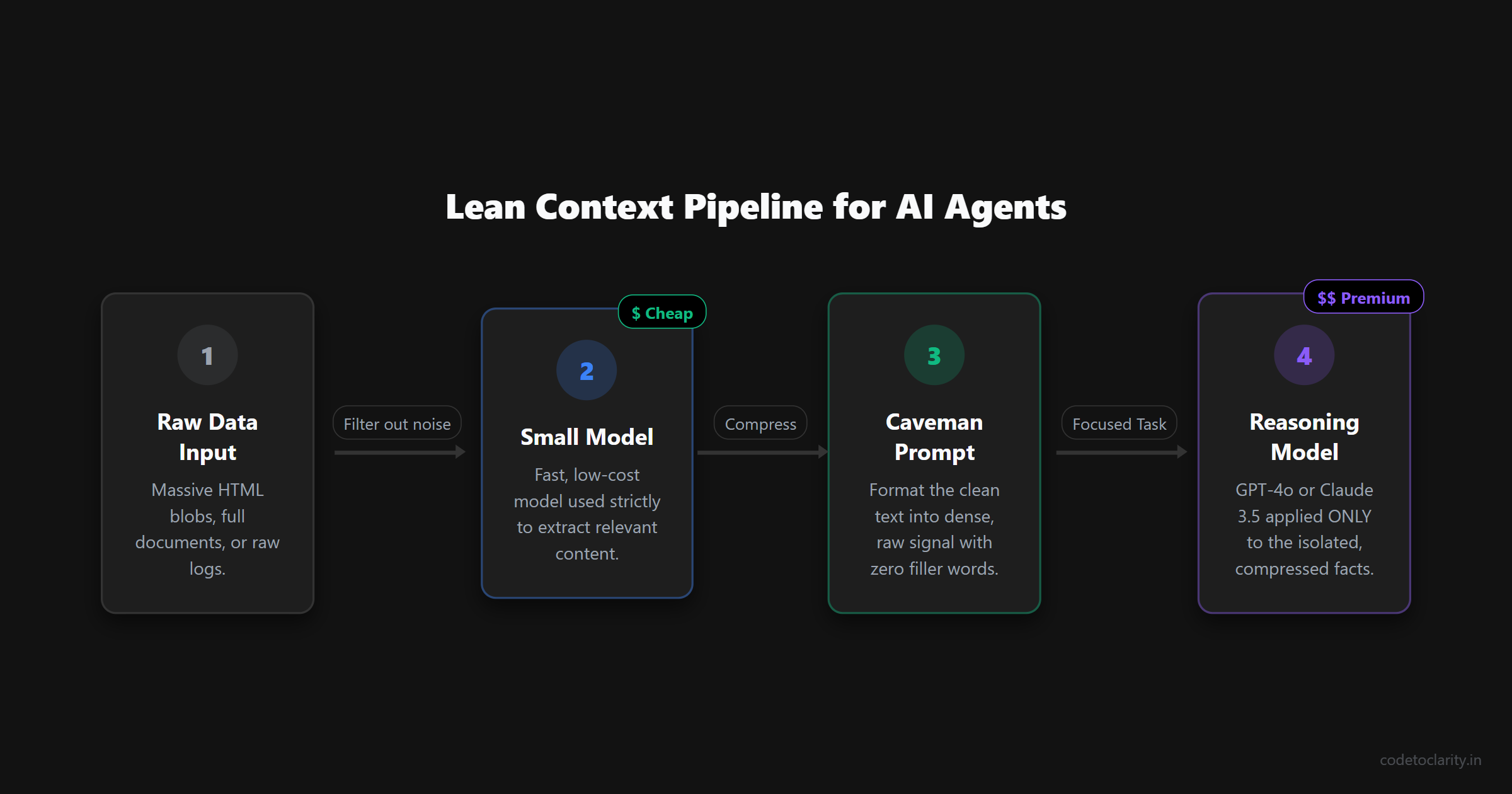
By applying these layers of compression, the system stays lean and fast. Developers building autonomous systems must learn to treat context windows exactly like computer memory in the early days of programming. Every kilobyte mattered back then, and every token matters right now.
The Future of Lean AI Systems
As we move into an era dominated by autonomous AI agents, token efficiency will become a central competitive advantage. An AI agent might run in a background loop, calling the language model hundreds of times an hour to evaluate data, scrape websites, or test code.
If your agent is bloated with unnecessary context and overly conversational prompts, a task that should cost cents will end up costing dollars. Mastering Context Engineering and strategies like the Caveman Prompt ensures your systems scale cleanly, reliably, and affordably.
Conclusion
The magic of modern AI lies in its flexibility, but that same flexibility can lead to immense waste. By treating tokens as a precious resource, separating your chats, and compressing your prompts, you unlock much faster, cheaper, and more intelligent systems. Start trimming the fat from your prompts today, and watch your API bills drop significantly. Learning to communicate like a caveman might just be the most sophisticated technical skill you acquire this year.

Kishan Kumar
Software Engineer / Tech Blogger
A passionate software engineer with experience in building scalable web applications and sharing knowledge through technical writing. Dedicated to continuous learning and community contribution.